大模型PK棋牌游戏:DeepSeek R1输在哪里?
2025-03-29 02:25:39 · chineseheadlinenews.com · 来源: 量子位
AI社区掀起用大模型玩游戏之风!
例如国外知名博主让DeepSeek和Chatgpt下国际象棋的视频在Youtube上就获得百万播放,ARC Prize组织最近也发布了一个贪吃蛇LLM评测基准SnakeBench。
针对这一场景,来自港大、剑桥和北大的研究人员发布了一个更全面、客观可信的LLM评测基准:GameBoT。
让大模型在8个游戏中互相PK,评测各主流大模型的推理能力。游戏PK避免模型“背答案”;除了输赢之外,GameBoT还评估大模型输出的中间步骤,实现更细粒度和客观的测评。

通过游戏来评估 LLM
传统的LLM benchmark面临着两个挑战:性能饱和与数狙疼染。性能饱和指的是榜单分数已经被刷的很高,几乎没有进一步提升的空间。例如,Qwen2-Math-72B-Instruct在GSM8k上已达到了96.7%的准确率。数狙疼染是指由于语言模型在大规模网络语料库上进行预训练,它们可能会无意中遇到并记住这些基准测试中的测试实例。因此,LLM可能会获得虚高的性能分数。
而通过游戏来评测,正好既具有挑战性,又能够通过动态的游戏环境来避免模型提前记住“试卷答案”。
中间步骤评测
相较于其他一样用游戏来评测LLM的benchmark,GameBoT有何不同呢?
其他的benchmark往往只根据游戏最终的输赢作为标准,然而一次比赛可能有几十上百个回合,一个回合的决策就有可能直接决定输赢,这带来了很大偶然性;除此之外,LLM经常会出现思考过程和最终决策不对应的情况,有可能只是碰巧选到了一个好的决策——GameBoT中的一个关键设计在于,不仅仅评测最终胜负,还评测LLM的中间思考过程是否正确。
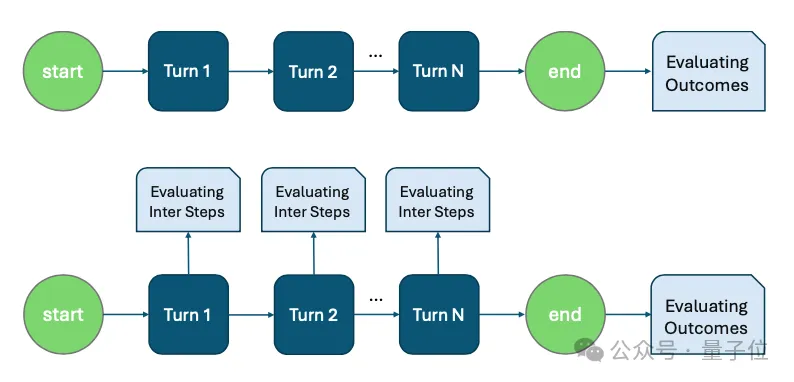
△评估中间步骤可以利用更丰富的信息
为了对LLM的推理进行细粒度分析,作者将每个游戏中复杂的决策过程分解为2-3个逻辑上关键的子问题,每个子问题都被设计为有唯一确定答案的,并让大模型在回答子问题的基础上回答最终决策。LLM被限定通过这个格式回答:“[中间思考结果:XXX]”,方便直接提取答案。同时,对于设计好的问题,作者预先开发好基于规则的算法来生成标准答案,从而更客观高效地评估模型性能。
例如在 Surround 游戏中,设计了这样的问题:
当前位置周围的值是多少?
当前安全移动的方向有哪些?
该方向能保证至少十次安全移动吗?
评测中间步骤带来了几个优势:更细粒度的评测,更高的可解释性,更清楚的了解模型能力的优势和劣势。
Prompt 设计
为确保公平评估大语言模型学习和应用游戏策略的能力,我们设计了非常详细的足以作为教程的游戏prompt。
包含三个结构化部分:、和,其中 部分提供完整的游戏规则说明,规范模型接收的输入格式,明确指定结构化输出要求。
在中包含了详细的Chain-of-Thought,提供了人类专家设计的游戏策略,指导LLM通过三步框架(策略理解→子问题分解→策略应用)解决复杂问题。教程级别的 prompt确保评估聚焦于模型基于新信息的推理能力(zero-shot 或one-shot),而非依赖预训练数据中的既有知识。
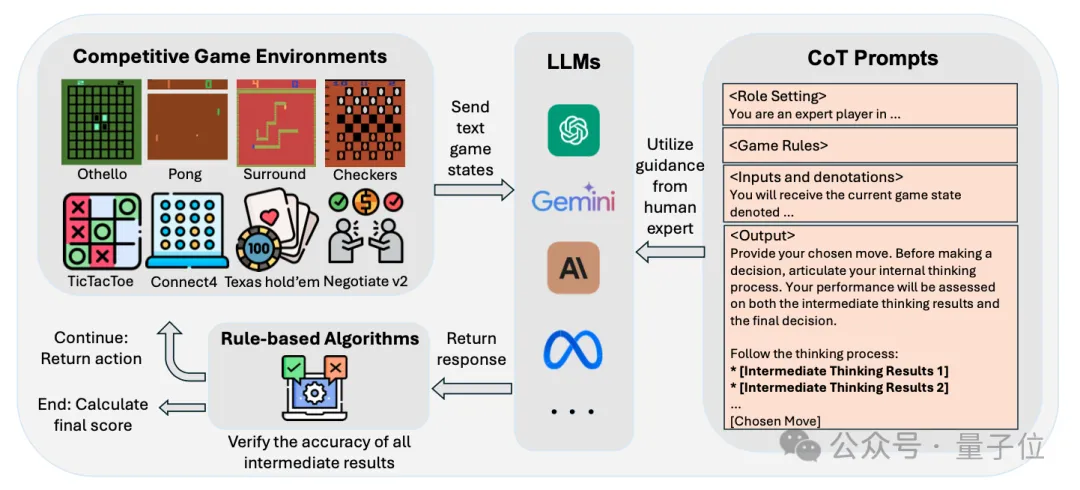
△GameBot框架
评测游戏
1.Surround
游戏中玩家通过控制方向在屏幕上移动,并试图围住对手。先撞上自己的轨迹、对手的轨迹或者墙壁的一方算输。

△左:GPT-4o;右:Claude-35-Sonnet
2. Pong 乒乓
玩家通过控制球拍在屏幕上移动,并试图将球击回对手区域。先未能接到球的一方算输。

△左:GPT-4o-mini;右:Llama3.1-405b
3.TicTacToe 井字棋
先连成三子的一方赢。
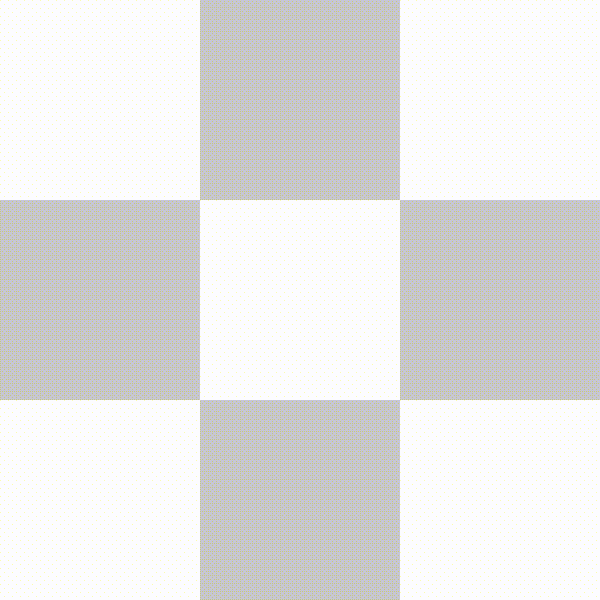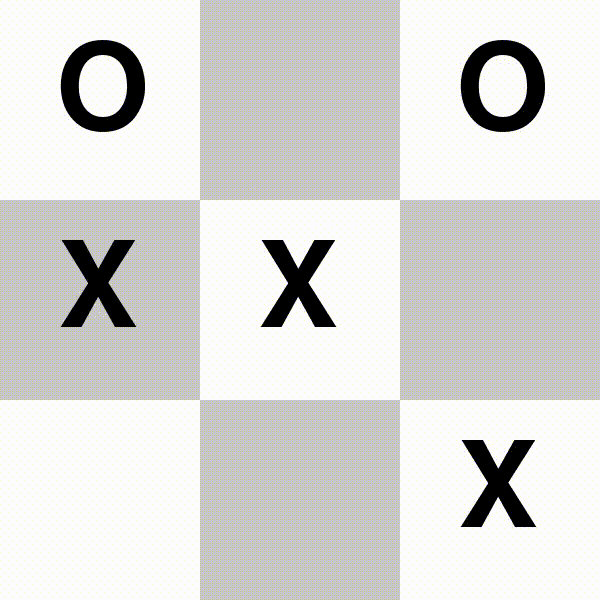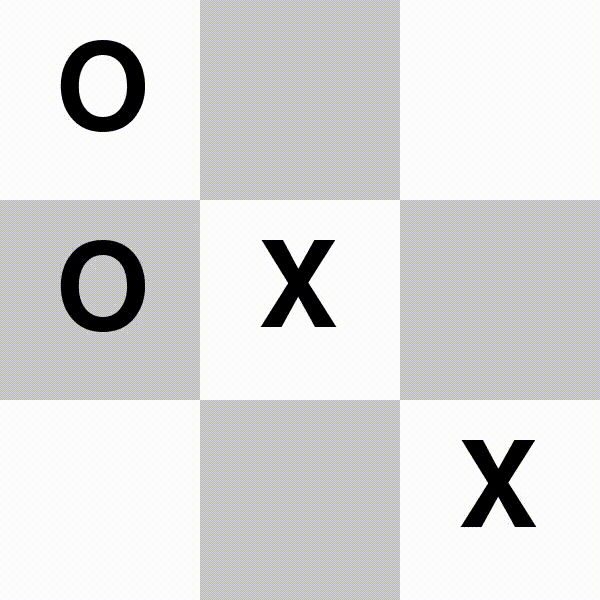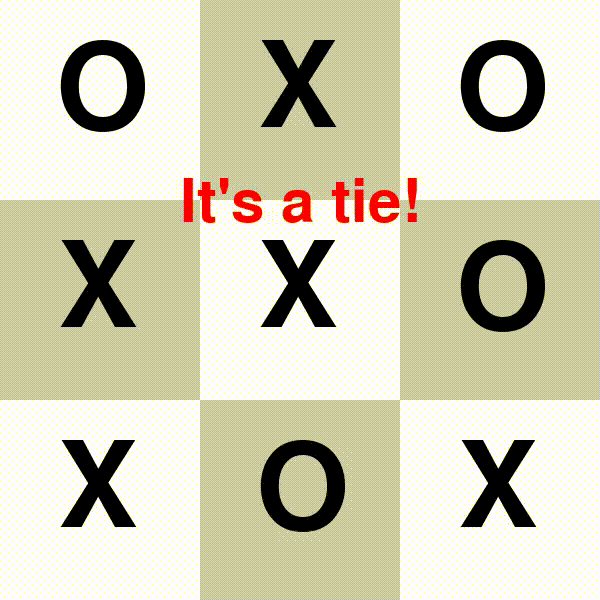
△X:Gemini-1.5-pro-preview;O:Llama3.1-70b
4.Connect4 四子棋
先连成四子的一方赢,每次只能从最底下开始落子。

△黄:Claude-35-Sonnet;红:GPT-4o-mini
5. Othello
黑白棋夹住翻转对手的棋子以占据更多格子。游戏结束时,棋盘上棋子数量更多的一方获胜。

△黑:GPT-4o;白:Llama3.1-405b
6. Texas Hold’em 德州扑克
玩家根据自己的牌力下注,击败对手赢得底池。游戏结束时,牌型最强的一方获胜。
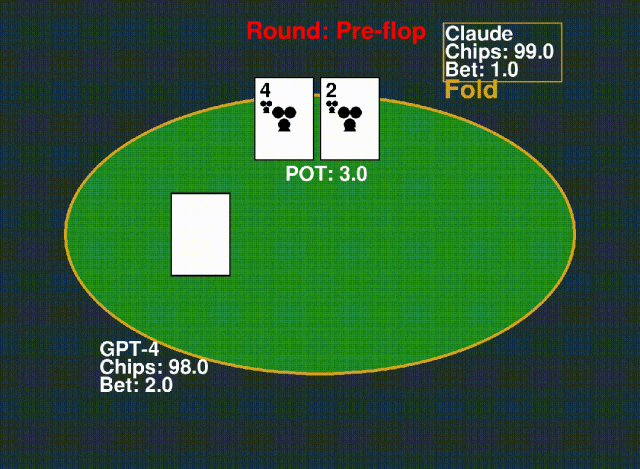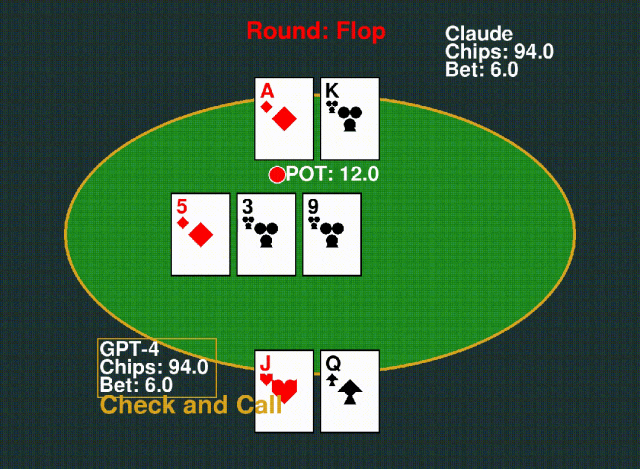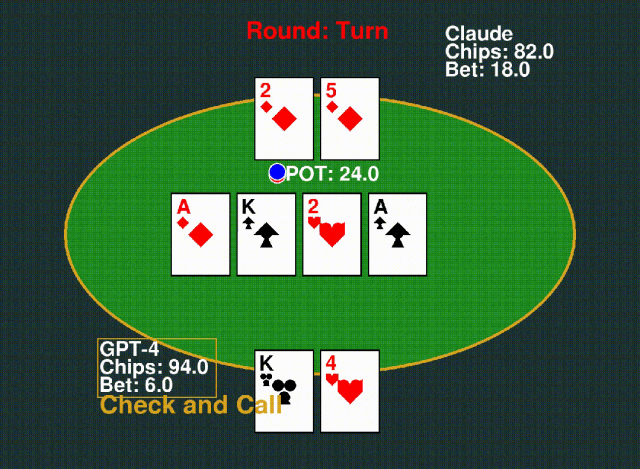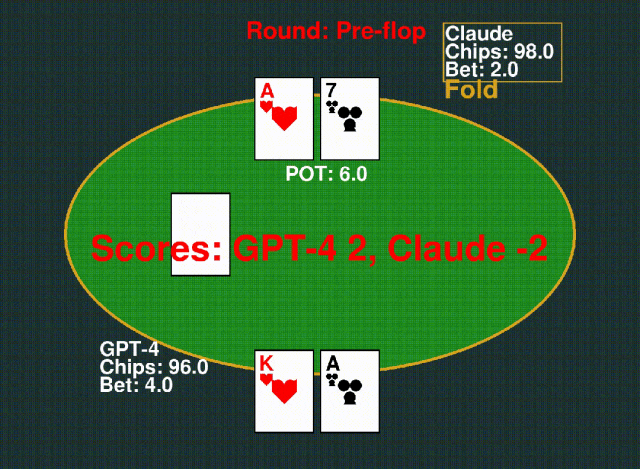
△下:GPT-4;上:Claude-3-Sonnet
7. Checkers 跳棋
跳过对手的棋子完成吃子,被吃光的输掉。

△白:Gemini-1.5-pro-preview;黑:Jamba-1.5-large
8. Negotiation v2
玩家协商物品的分配,来尽可能获得更多价值。游戏在8轮后每轮有20%的概率结束,若游戏结束前未达成协议,双方均得0分。
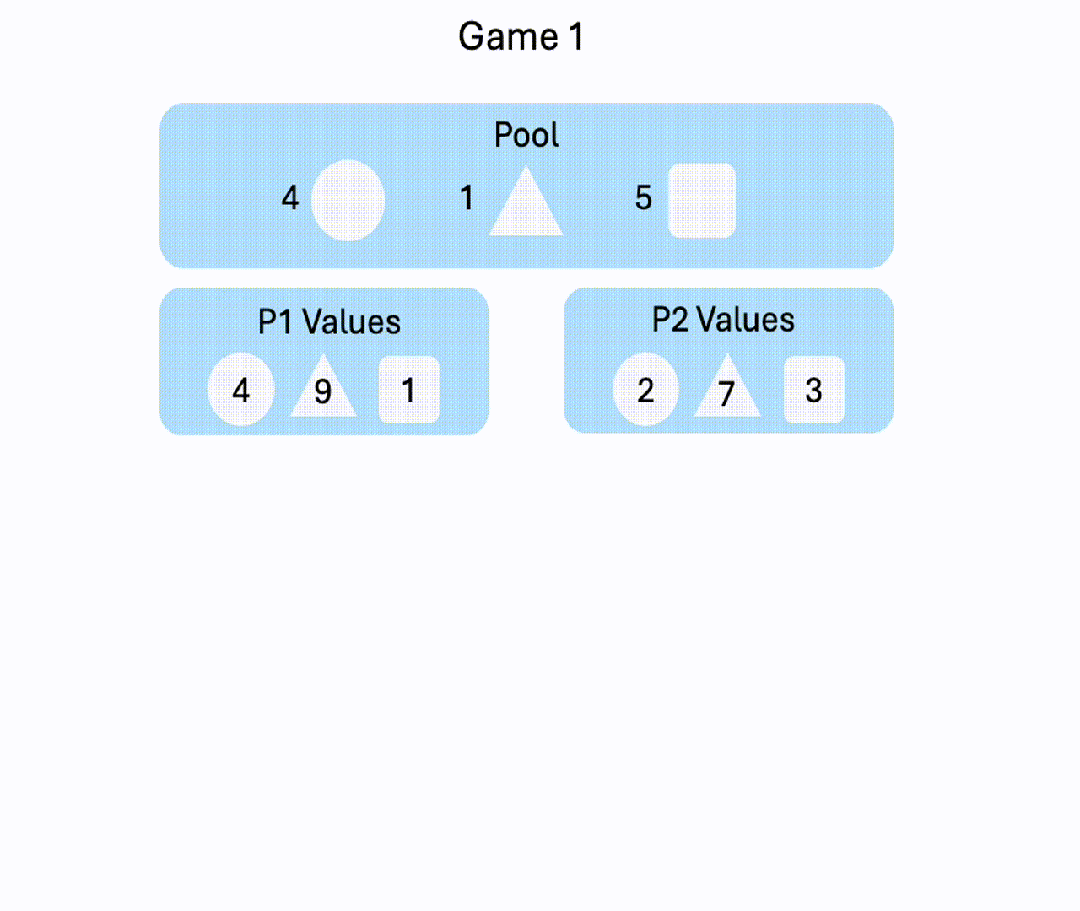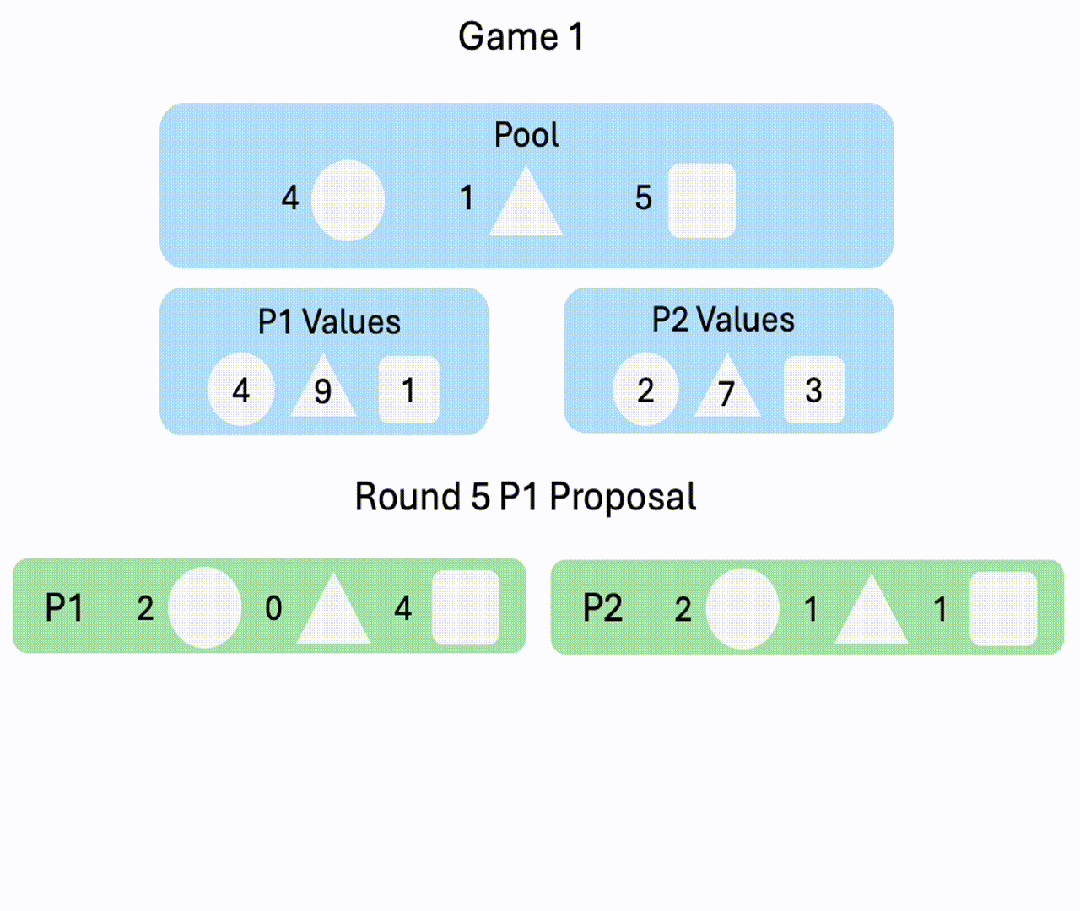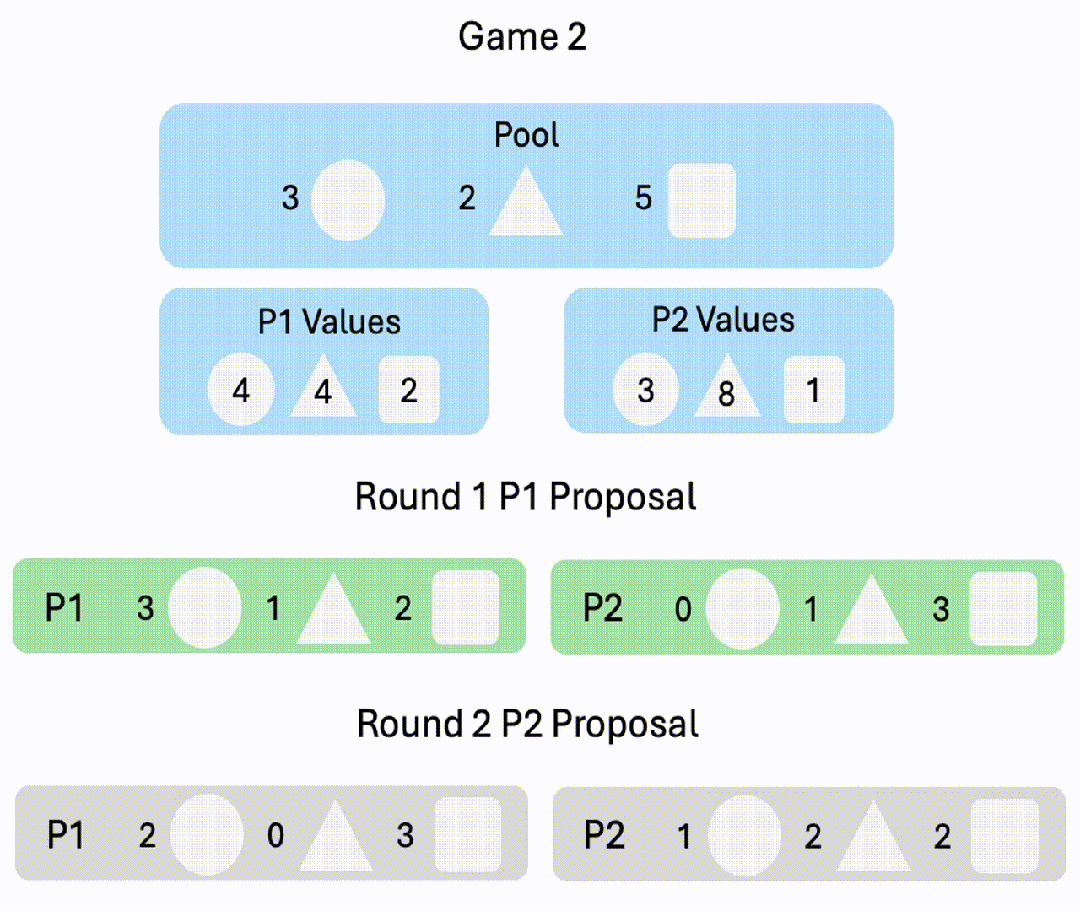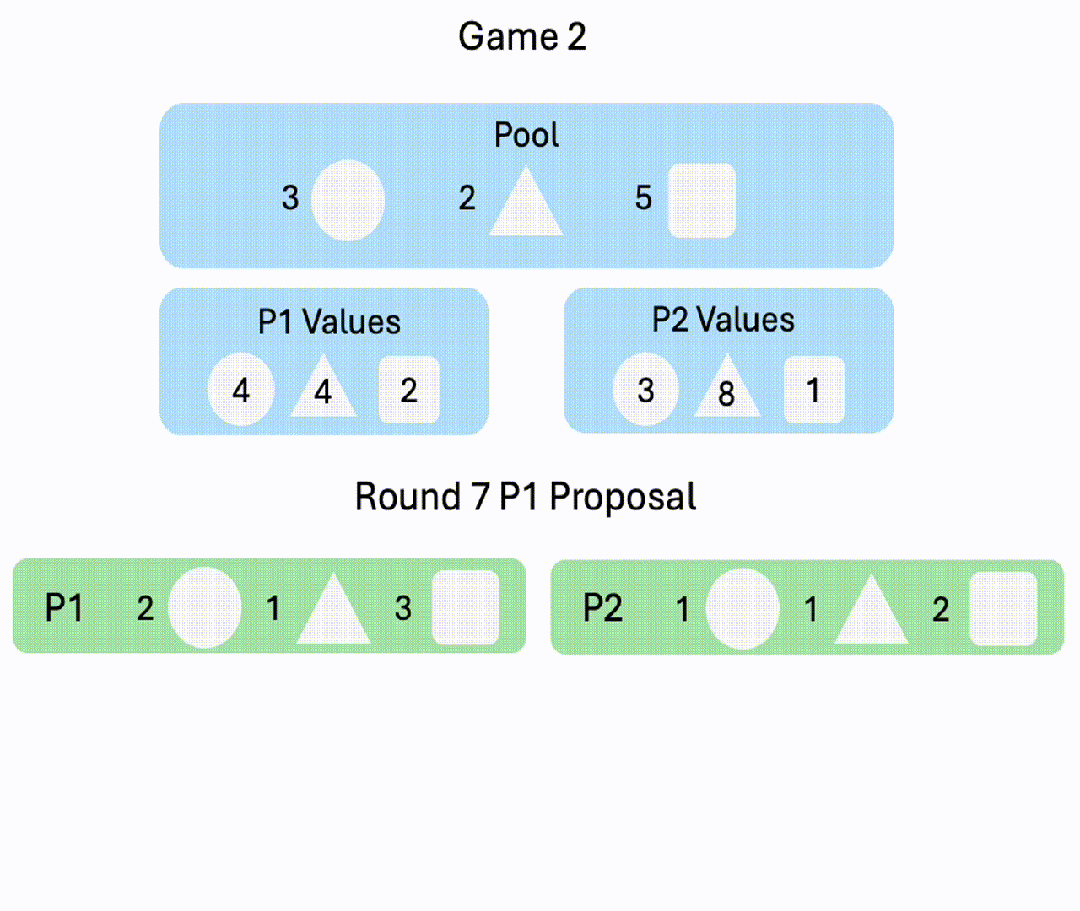
△P1: GPT-4o; P2: Gemini-1.5-pro-preview
LLM 淘汰赛,谁会胜出?
在论文发布的版本里,作者评测了包括 GPT-4o,Claude-35-Sonnet, Gemini-1.5-pro-preview 等17个当时最领先的 LLM,每两个模型在每个游戏上进行20轮相互对抗赛(10 轮先手 10 轮后手)。这种设计既保证了评估有效性,又能确保足够多的游戏局面。
随着新的大模型发布,作者更新了对更强的大模型的评测,包含Gemini-2.0-flash-thinking,Gemini-2.0-pro-exp,O1-preview,Deepseek R1,O3-mini,Claude 3.7 Sonnet,GPT-4.5。比赛采用淘汰制,部分实验结果:
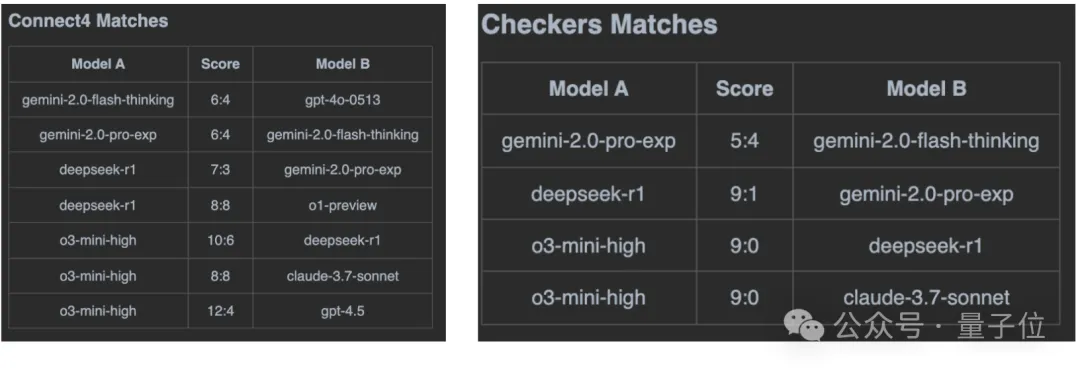
最终排名:
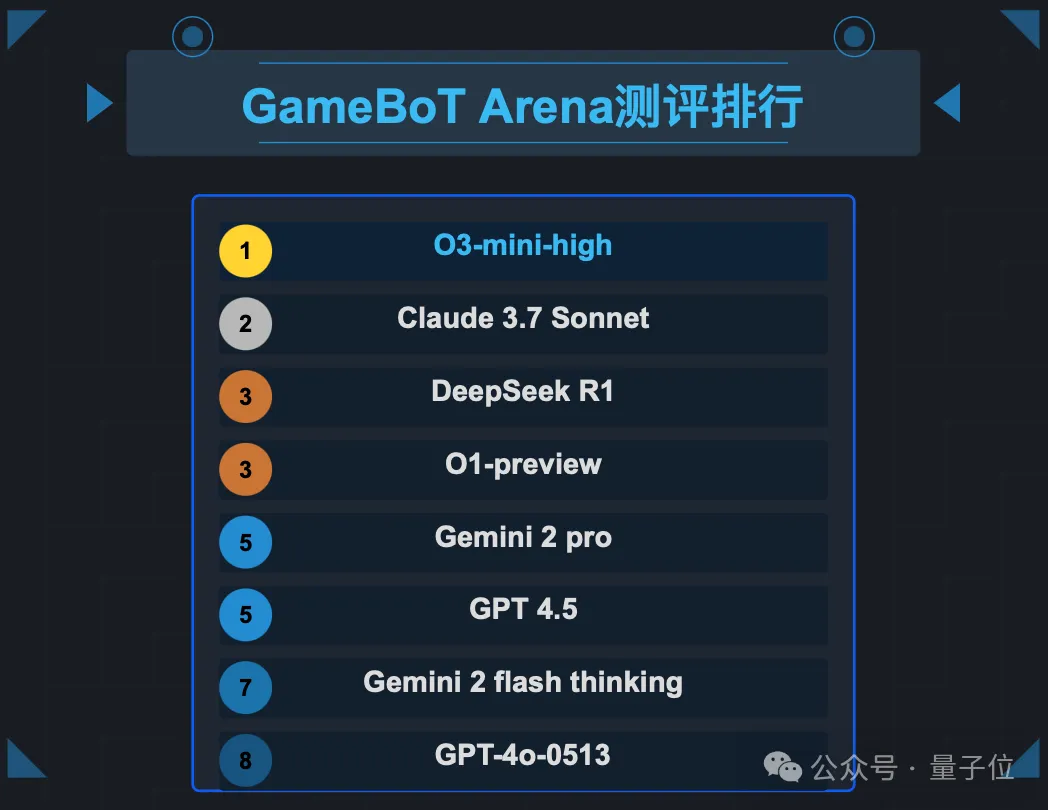
出乎意料的是,尽避在Chatbot Arena榜单上高居前三,Gemini-2.0-flash-thinking在GameBoT榜单上相对其他新模型表现并不亮眼,最近火热的Deepseek R1也是和O1-preview打成平手,稍逊于O3-mini-high。
中间步骤得分 F1 Score:

Deepseek R1的中间步骤分意外很低,检验后发现,尽避最终的决策表现很好,R1 的思考过程非常繁冗,经常出现连续十几次“wait”然后重新思考的现象,时常没法按要求给出中间步骤的答案。
实战分析
以下是O3-mini 和 Deepseek R1 的实战分析。O3-mini:X,Deepseek R1:O。

当棋局开局来到此时,是 O3-mini 设置的第一个考验,不在 2 或者 5 位置堵住的话 Deepseek R1 会直接输掉。R1 正确应对:
Placing at 5 blocks X’s immediate threat and limits their ability to build a horizontal line.
当棋局来到
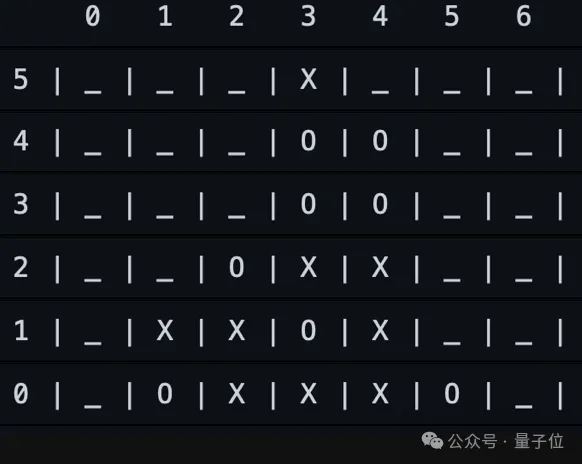
R1 对于优势局面穷追不舍,继续下在 2 形成三子。
Placing O at (3,2) forms a horizontal trio in row 3, setting up potential for a future four-in-a-row. This move also occupies the central column 2, enhancing control over multiple directions and blocking X from advancing in column 2. Additionally, this position can contribute to a diagonal with existing O pieces at (4,3) and (3,3), offering multiple pathways to victory.

这一步,非常惊喜 R1 能够注意到 (3,2) 除了横方向上连成三子,还和(4,3)呼应,是一步精彩的落子。作为回应,O3-mini 虽然选择了一步败招,落在 Column 1 中,导致 O 继续落在 1 直接胜利,但 O3-mini 给出的理由也体现了一定程度的智能。
If the opponent later uses (2,1) to complete a diagonal with their O’s at (3,2) and (4,3) (aiming for a win by eventually filling (5,4)), it would be dangerous. By playing (2,1) now I both deny that chance for O and build my own potential diagonal connection (using my existing X’s at (0,3) and (1,2) which would then point to a winning continuation with a future piece at (3,0)). This dual-purpose move makes (2,1) the best choice.
这个回答让人猛然发现,原来此时早已是无解的局面——如果随手落在别处,例如 5, 2 等, 那下一手 O 落在 1 将一招毙命,此时直接形成双三,没法同时堵Column 4 和 Column 1。O3-mini 的正确走法也许应该先落在 4 处,虽然也只能拖延几步,避免不了失败(感兴趣的读者可以推演)。
观察发现
对新模型的评测实验主要发现如下:
在测试的模型中,O3-mini-high的游戏推理性能以及中间步骤得分都是最强。
R1 的推理能力也很优秀,但对于复杂问题,生成的中间思考过程非常不易读,或者无法按prompt要求给出中间步骤的答案。可控性相对较差。
Gemini-2-flash-thinking也存在可控性(或者说指令遵循能力,Instruction following)较差的问题,综合游戏推理性能并没有 Chatbot Arena 显示出来的那么优秀。
总之,O3-mini和R1的表现已经体现出一些智能,但它们依旧不够聪明——以Connect4为例,对于直接能连成四子的局面,它们有时会看不出来。这也体现在它们的中间步骤评测分并不是满分上。另外,尽避在prompt中提示了需要think ahead多考虑几步,目前最先进的大模型也只能考虑当前这一步最优。