手机实现GPT级智能,极致的稀疏技术
2025-04-12 02:25:27 · chineseheadlinenews.com · 来源: 量子位
在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。
端侧部署一直是大模型落地的最后一公里,却因算力瓶颈困难重重。
面壁智能和清华走出了一条与MoE不同的路径——神经元级稀疏激活,让模型在保持性能的同时大幅降低资源消耗。
这次技术探索的背后,是一个融合脑科学灵感与工程创新的故事。

△《Configurable Foundation Models: Building LLMs from a Modular Perspective》论文
本期“大模型创新架构”主题访谈,量子位邀请到面壁智能&清华CFM论文作者肖朝军,聊聊这场算力与效率的博弈以及大模型架构创新的未来。
以下为量子位与面壁智能&清华CFM论文作者肖朝军的对话实录整理:
探索原生稀疏
量子位:能简单介绍一下CFM(Configurable Foundation Models)技术的核心优势吗?
肖朝军:CFM是一种原生稀疏技术,利用模型本来就有的稀疏激活性质,相比MoE可以极大提升模型参数效率。
量子位:参数效率是什么?极大提升参数效率意味着哪些优势?
肖朝军:参数效率是指模型单位参数的有效性,一般能够反映在相同参数规模下,模型是否表现更好。参数效率提升最直接的影响就是省显存、省内存。
尤其手机端不可能像云端一样用好几台GPU服务器一起推几千亿参数规模的模型。手机内存有限,操作系统占一部分,个人应用需要一部分,如果大模型把内存占满,那手机基本上就不可用了,所以参数效率在端侧应用里非常重要。
量子位:CFM与MoE(Mixture of Experts)的区别在哪里?
肖朝军:我们的稀疏粒度更细,更强调神经元级别的稀疏,可以说CFM的颗粒度比其他许多在FFN层做稀疏化改进的工作要更细,在稀疏化上走得更极致。
现在超大参数规模的MoE稀疏化可能已经成为主流,但不适合端侧。MoE的稀疏粒度是专家级别,CFM是神经元级别,而且CFM动态性也强于MoE。MoE固定激活Top k个expert,CFM是靠模型自己的激活函数来定义具体激活多少expert。
任务难的话可能需要激活10-100个,任务简单可能就激活1-2个。
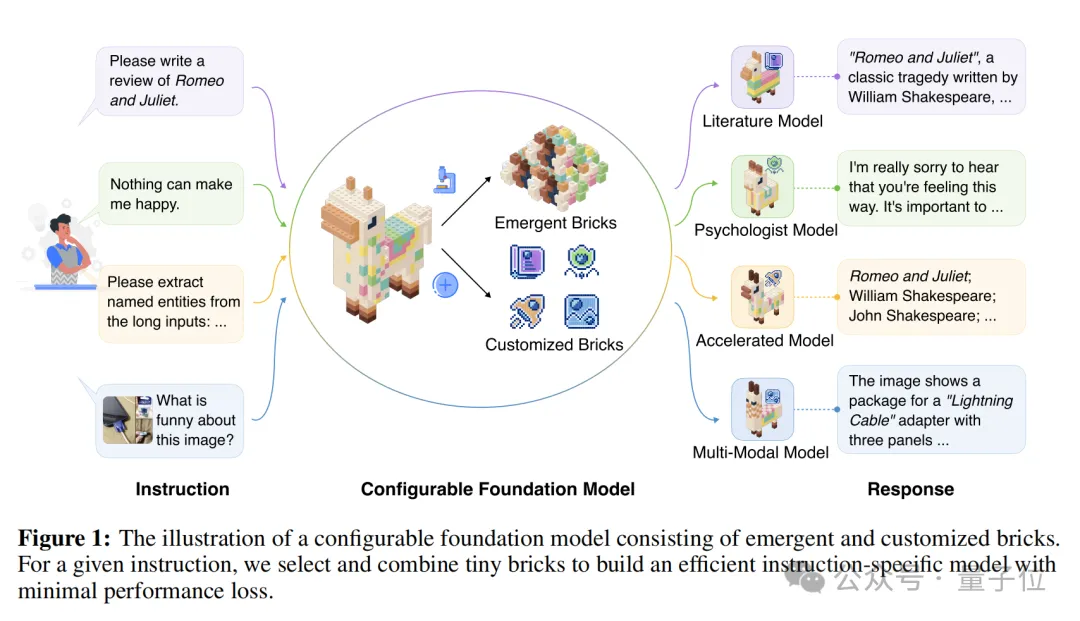
△CFM积木式组合构建高效任务模型
量子位:为什么MoE不使用你们这种更强的动态性?
肖朝军:本质是参数效率原因。
MoE的目的是增大模型参数,比如600B的模型无法在一台机器上放下,必须在训练过程就卡死激活专家的数量,必须限制住最多激活top k或top p个专家,要不然就可能算不下了。
他们必须在训练阶段就要有负载均衡的loss,使每个expert和每个token大致均衡。而我们参数效率高,所有参数可以放在一起像传统稠密模型的FFN一样计算。
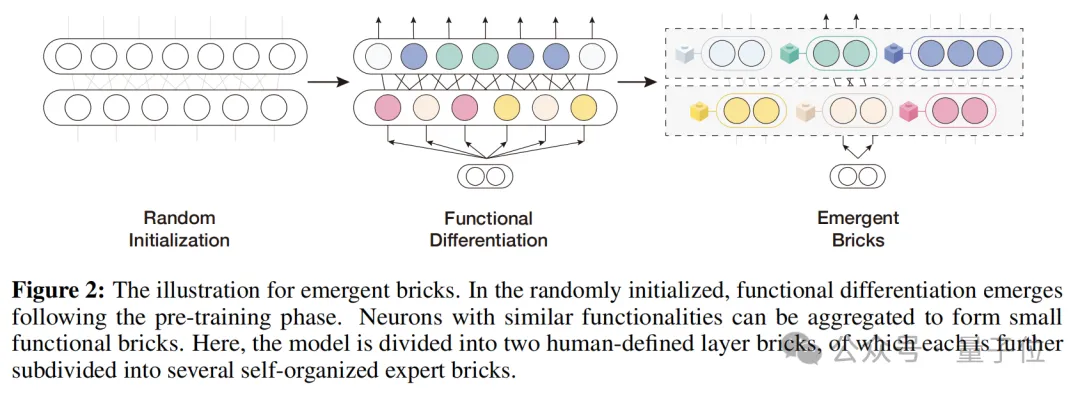
△涌现模块的形成过程示意图
模型架构之争
量子位:你怎么看待像Mamba、RWKV这些计算复杂度为线性的非transformer架构模型带来的挑战?
肖朝军:从模型效果上来说,transformer仍是天花板最高的架构。当前所有其他的非transformer架构探索都是在做效率,而不是效果。
我观察目前优化路径大概有两种:
一种是线性派,包括Mamba、Linear Attention、Gated Linear Attention、RWKV等;
另一种是基于transformer,但对KV cache做管理,比如KV eviction、KV compression等。做FFN改进的其实不多,我们强调的稀疏可能是FFN改进中非常重要的一点。
量子位:很多非transformer架构都在多个测试集上打败了主流transformer模型,你怎么看?
肖朝军:需要辩证看待。
首先要考虑公平性,比如Mamba实际上有固定的memory,在短文本时可能memory size更大,这可能是用更多存储换取包好效果。
像RULER等一系列长文本评测中,线性模型目前还是打不过transformer。大家报的结果都是”在某方面比transformer好”,但为什么没有广泛应用?因为没办法全面打败transformer。
量子位:今年1月份大模型六小强中的一家训的千亿参数线性attention模型在RULER上打败了GPT-4o、Claude-3.5-Sonnet等transformer模型,你怎么看?肖朝军:他们的模型是混合架构,纯线性很难做到同样的表现。但能有这样的成绩说明他们混合之后的效果还是很厉害的。
量子位:如何才能客观评价模型架构之间的优劣?
肖朝军:确实很难有一个放之四海而皆准的评判方式。transformer之所以取代CNN和RNN成为主流,是因为它真的能scaling。
之前的架构是scaling不了的,transformer带来了一种新可能性:我们可以训练很大的模型,用很多数据获得更多智能。而且它不需要任何trick,不需要人为调参就能获得好效果。
量子位:你认为transformer成为主流架构有偶然性吗?
肖朝军:既有偶然性也有必然性。有个概念叫“硬件彩票”。
软件往往走在硬件前面,我们会开发很多算法,但真正实现加速的是被硬件厂商选中的那种。transformer高强度对着GPU设计,真能打满GPU利用率,所以踩中了硬件彩票。
现在的Mamba、RWKV谁能踩中下一波硬件彩票,谁也说不准。

△硬件彩票内涵
小模型与智能未来
量子位:目前一个小模型的定义是多大size?最小能在什么尺寸的模型里压缩进主流大模型的能力?这个极限在哪?
肖朝军:现在小模型的大小没有明确定义,基本上端侧的话,可能还是在2-3B的范围算小模型。
关于模型压缩极限,我们发表过Densing Law的论文,但极限在哪里我们确实还不知道。很多人问未来是不是用64个比特就能放下GPT-4,那显然不可能,但具体极限还不明确。
量子位:智能的本质是压缩吗?
肖朝军:这样说有点怪。之前有一篇“语言模型即压缩”的论文,只是把压缩率和PPL做了转换,这很难说成本质。
Ilya最早提出智能本质是压缩这个思想的时候,强调的是“压缩器”能够很好地建模数据分布规律,而不是直接用语言模型来构建数据压缩器。
Hinton说过,智能的本质是学习,就是学习能力才是智能的本质。我认为抽象能力可能更接近智能本质。你看语言本身就是一种符号,能表征世间万物,承载人类知识,是抽象和总结的载体。
量子位:面壁智能的小模型落地情况如何?
肖朝军:我们开源的最大模型是是MiniCPM-3-4B,也有一些未开源的项目级模型可能有几十B。
我们的端侧场景很广泛,包括手机端、电脑端、智能家居等都在射程范围。

△面壁智能官网
量子位:精度优化方面,你们怎么看FP8等低精度计算?
肖朝军:精度降低后模型效果会变差,需要非常多的设计才能保证效果。
但现在DeepSeek已经开源FP8算子部分了,只要跟着做一些补全就行,现在再训新模型的只要有卡肯定都上FP8了,25年会更多人做FP8,做的更实用更激进。未来还会有FP4,一步步发展。
量子位:小模型在多模态方面有限制吗?
肖朝军:效果都挺好的。小模型在多模态这块,从打榜上看差异没有那么大。你会发现多模态现在还没有一个非常漂亮的scaling law。
而且也还没有一个统一共识的多模态模型架构。知识能力上,小模型可能还有差距,差距主要体现在对知识的调度和理解上。
量子位:你怎么看o1的这条技术路线?
肖朝军:o1主要是用强化学习和高质量数据,强调强化学习和推理的scaling。当前强化学习整个推理过程很慢,硬件利用率也不高,这会使强化学习过程需要使用大量算力但模型思考步数不深、探索空间不够。
未来肯定会继续往高效的深思考方向发展,让模型能够生成超长的思维链,之后会像pre-training一样,先把强化学习的训练规模做上来,然后再往小做、往高效做。
量子位:超长文本推理会是transformer架构的下一个突破点吗?
肖朝军:对,CoT(思维链)是目前很重要的方向。这种长思考一定是下一波大家要突破的点。
目前o1这种长思维链和普通的长文本大海捞针完全不同。大海捞针只是找到信息就完事了,而o1的长思维链需要回到当时的状态,重新做推理、重新搜索。
思考的时候走一条路走到底之后,可能还要继续之前考虑过的另一条路。现有测试集都很难全面评测o1这种长思维链能力。
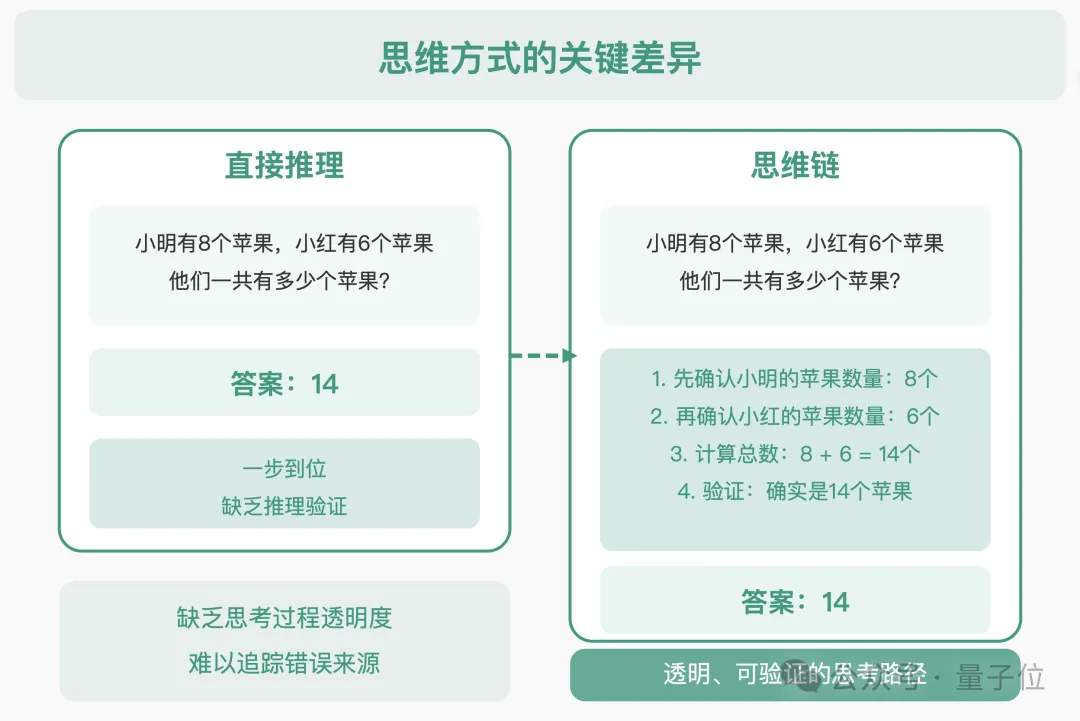
△直接推理与思维链区别示意
o1之后,我觉得下一步还有一个很重要的问题是创新能力的问题。就像OpenAI的技术规划,到后面有个innovation。
现在的搜索还是在已有的语义空间去搜索,但是真的要让AI去做创新出之前没有的东西,去探索一些新的未知的事物的时候,它一定要跳出之前预训练阶段见过的所有的东西去突破,但这个事情咋做?还不知道。
量子位:对于长文本推理,线性架构会有优势吗?
肖朝军:目前没有实证研究证明纯RNN模型的推理能力,我个人认为类RNN的线性架构技术路线大概率会失败,混合架构另当别论。
效果为王,解决不了效果问题,谈效率是不现实的。
现有RNN模型其实等价于滑动窗口,在推理中会对记忆不断乘一个遗忘系数。即使遗忘系数连续一万步都是0.999这么大,那一万步之前的内容也会遗忘完,上限天然太低。
量子位:大模型不可能三角(大模型无法同时实现低计算复杂度、高性能和并行化)问题有解决方案吗?
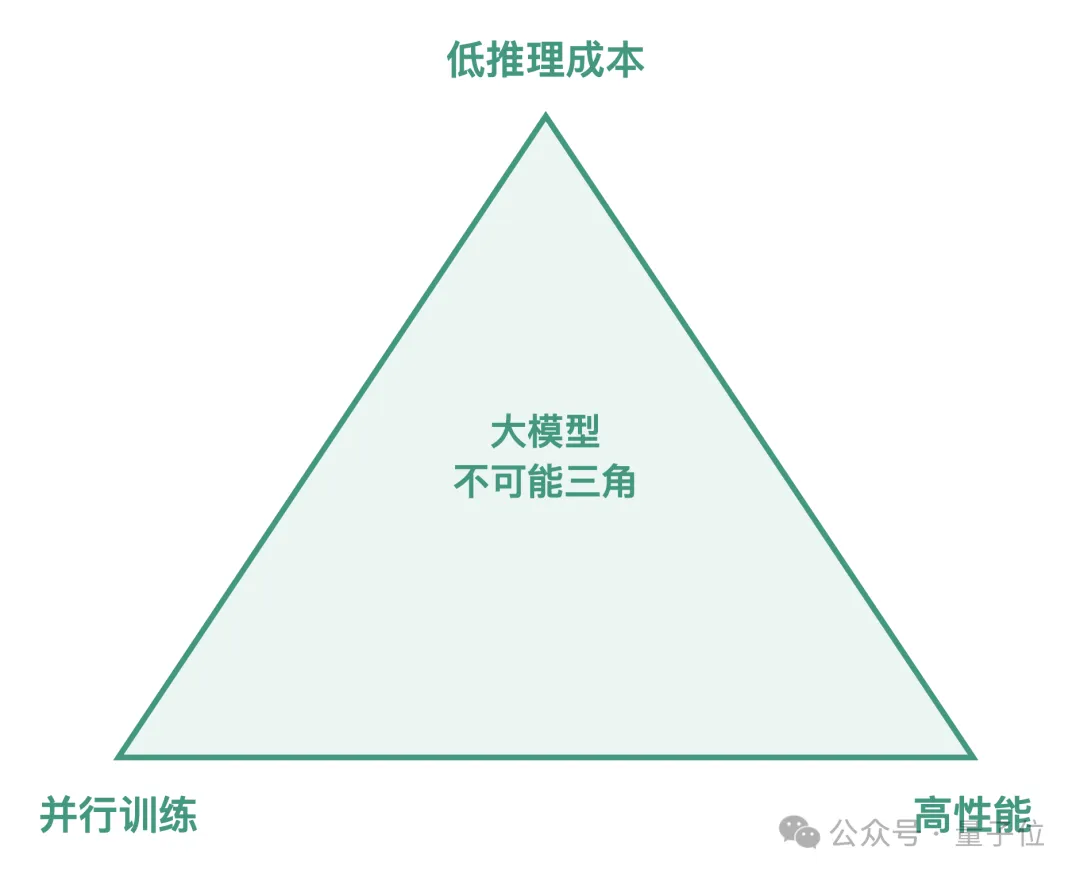
△大模型不可能三角示意
肖朝军:这个问题依旧存在,Mamba也依然没有解决。如果真解决了,现在大家都会用起来。
Mamba等线性模型在短文本上能与transformer打平或更好,但长文本上仍有压缩,而压缩一定代表信息损失。我们还是无法兼顾计算复杂度和效果。
这个问题也许长期来看可以解决,因为人类思考也不是O(n?)复杂度的,不需要把之前所有KV都算一遍。但人脑存储可能是分级的,有长期记忆和短期记忆,还可能利用外部工具如笔记本。具体怎么解决,目前还没有摸到答案。