Llama 4深夜开源击败DeepSeek V3
2025-04-05 21:25:44 · chineseheadlinenews.com · 来源: 新智元
原生多模态Llama 4终于问世,开源王座一夜易主!首批共有两款模型Scout和Maverick,前者业界首款支持1000万上下文单H100可跑,后者更是一举击败了DeepSeek V3。目前,2万亿参数巨兽还在训练中。

一大早,Llama 4重磅发布了!
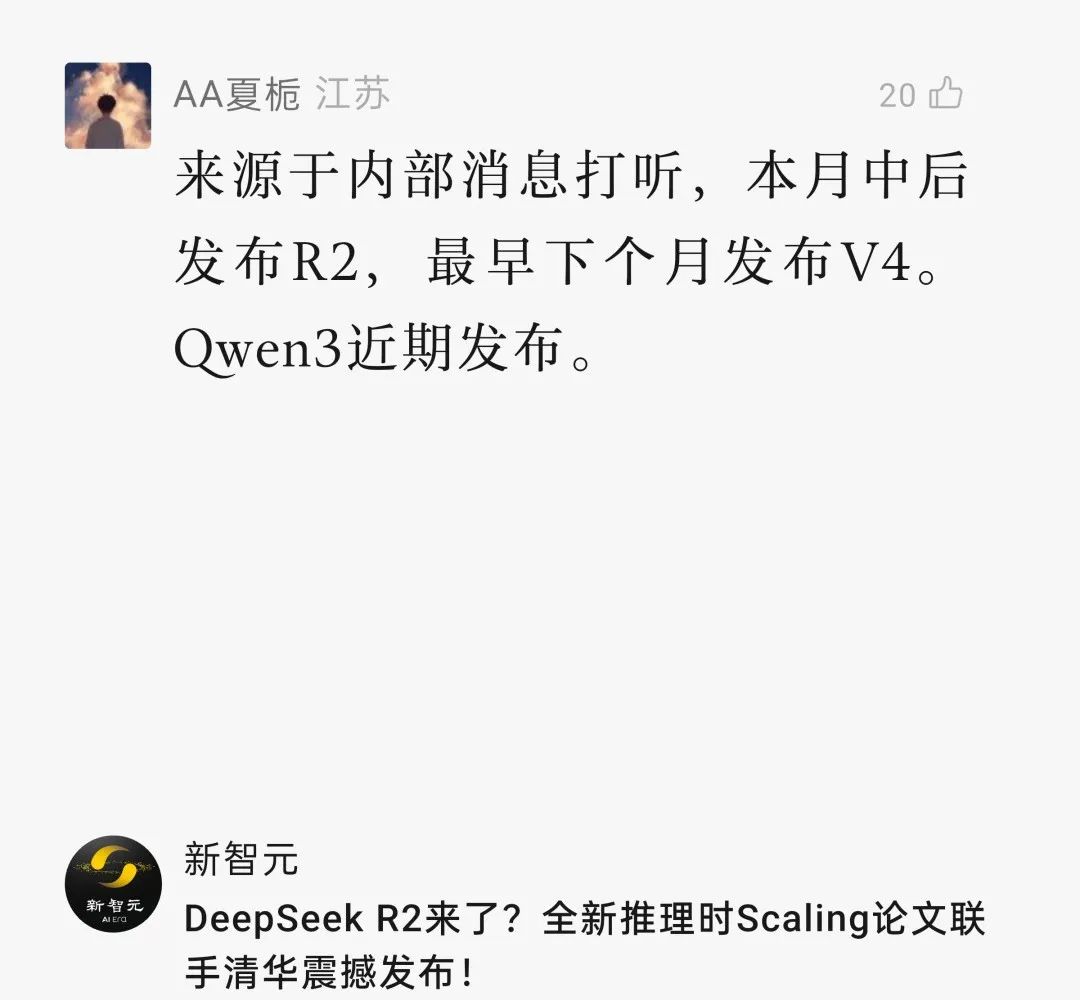
此前报道称,DeepSeek R2最晚在5发布,看来可能要提前了...
史上最强Llama 4开源,超越DeepSeek V3
Llama 4模型开源,标志着Llama生态系统进入了一个新纪元。

即日起,所有开发者可以在llama.com和Hugging Face下载这两款最新的模型
在大模型排行榜中,Llama 4 Maverick在硬提示(hard prompt)、编程、数学、创意写作、长查询和多轮对话中,并列第一。
仅在样式控制下,排名第五。
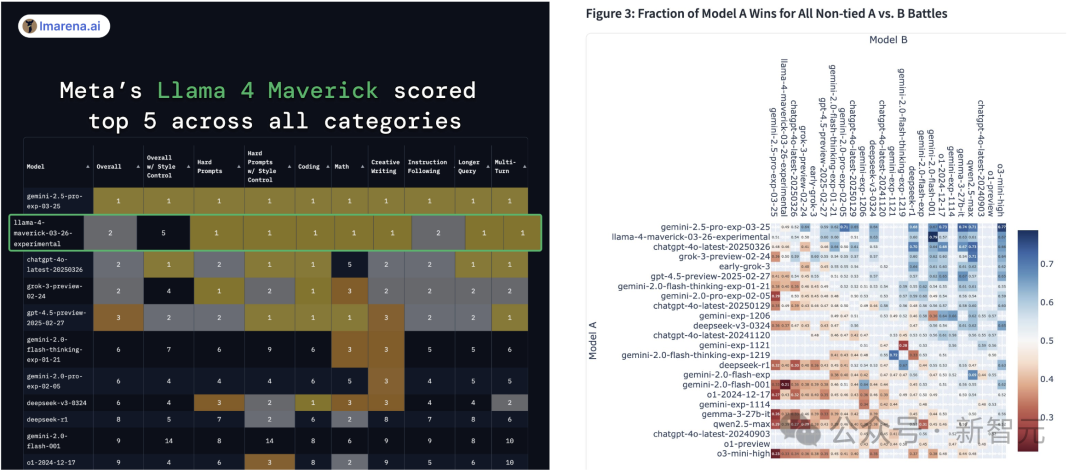
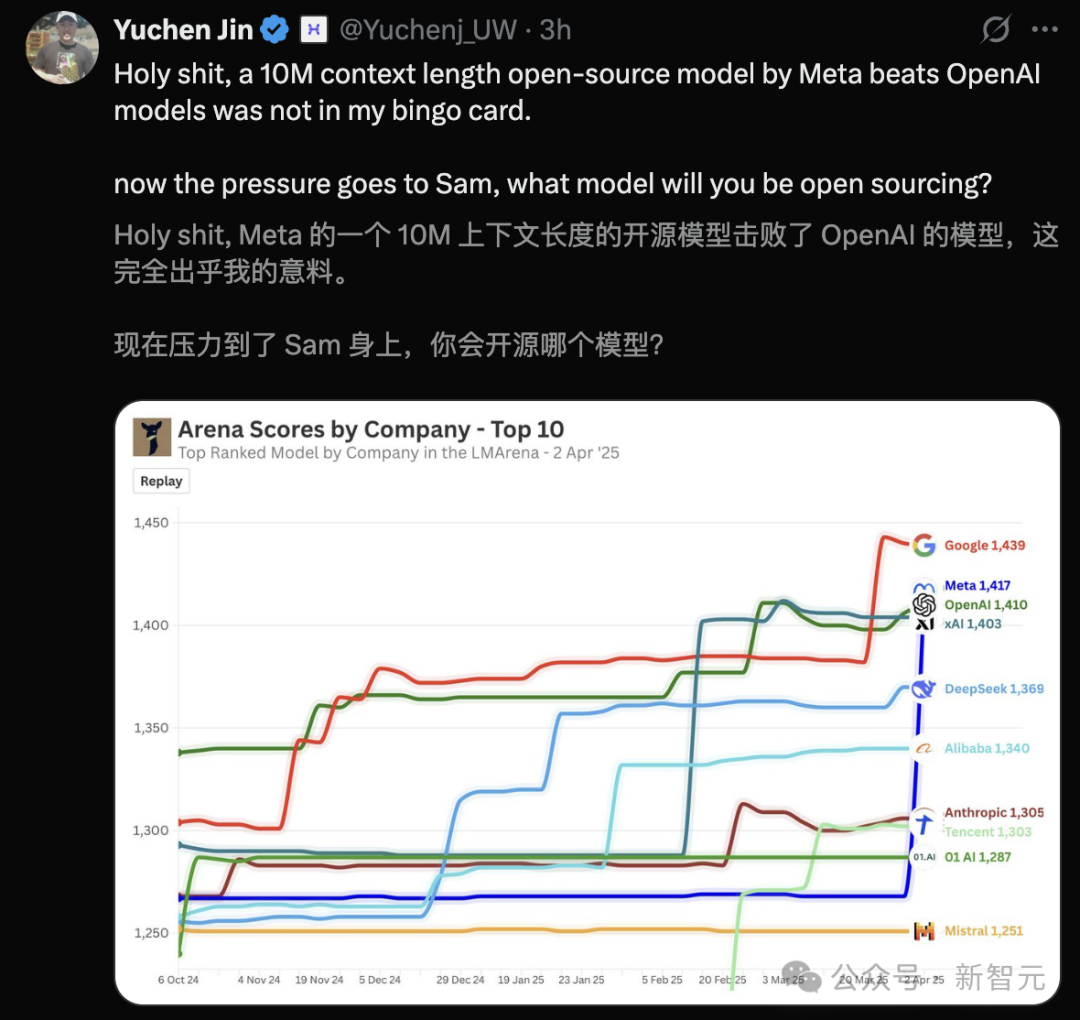
而且,1000万上下文Llama 4 Scout还击败了OpenAI的模型。
每个人还可以在WhatsApp、Messenger、Instagram Direct和网页上体验基于Llama 4的应用。
首次采用MoE,单个H100即可跑
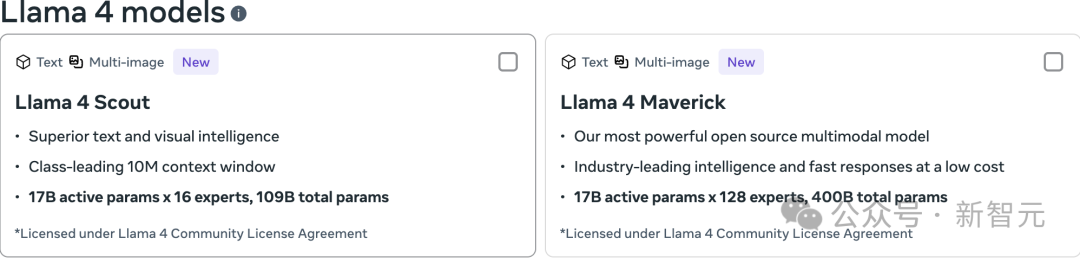
Llama团队设计了两款高效的Llama 4系列模型,只要单个H100 GPU就能运行:
一个是Llama 4 Scout(拥有170亿个活跃参数和16个专家),使用Int4量化可以在单个H100 GPU上运行;另一个是Llama 4 Maverick(拥有170亿个活跃参数和128个专家),可以在单个H100主机上运行。
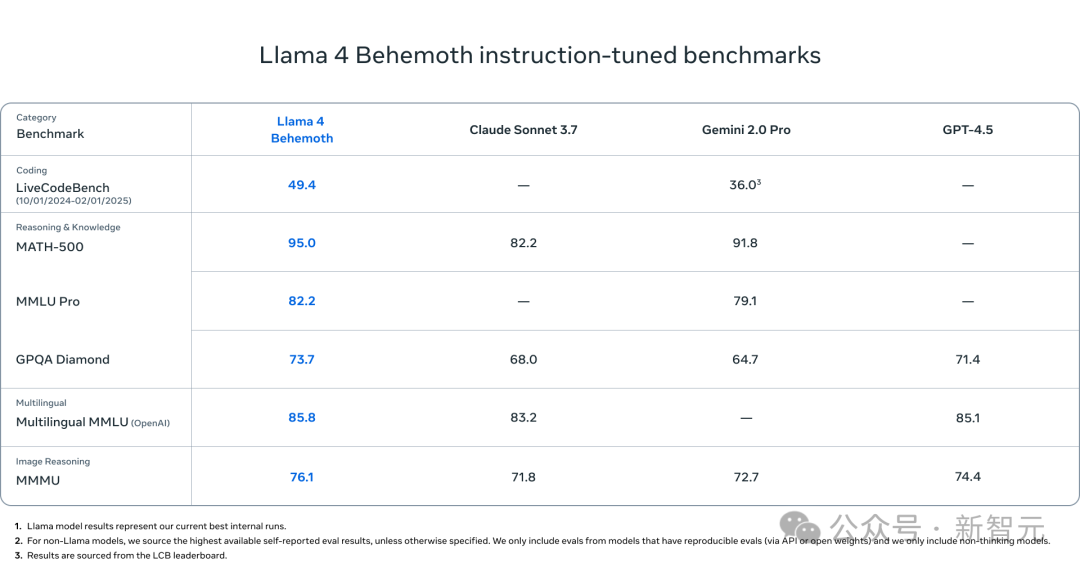
目前,正在训练的教师模型——Llama 4 Behemoth,它在STEM基准测试(如MATH-500和GPQA Diamond)中,性能优于GPT-4.5、Claude Sonnet 3.7、Gemini 2.0 Pro。
在最新博文中,Meta分享了更多的关于Llama 4家族训练的技术细节。
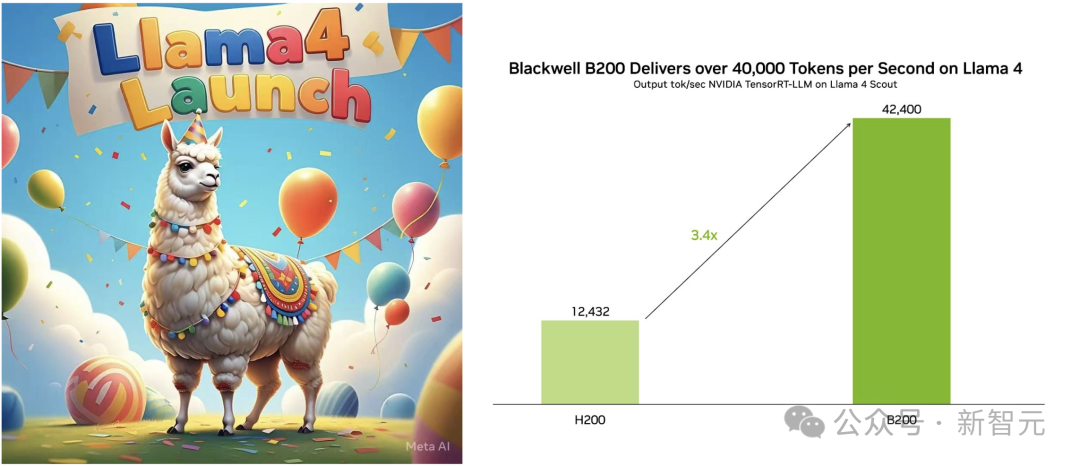
在英伟达B200上,Llama 4可以每秒处理42400个token
预训练
Llama 4模型是Llama系列模型中首批采用混合专家(MoE)架构的模型。
在MoE模型中,单独的token只会激活全部参数中的一小部分。
与传统的稠密模型相比,MoE架构在训练和推理时的计算效率更高,并且在相同的训练FLOPs预算下,能够生成更高质量的结果。
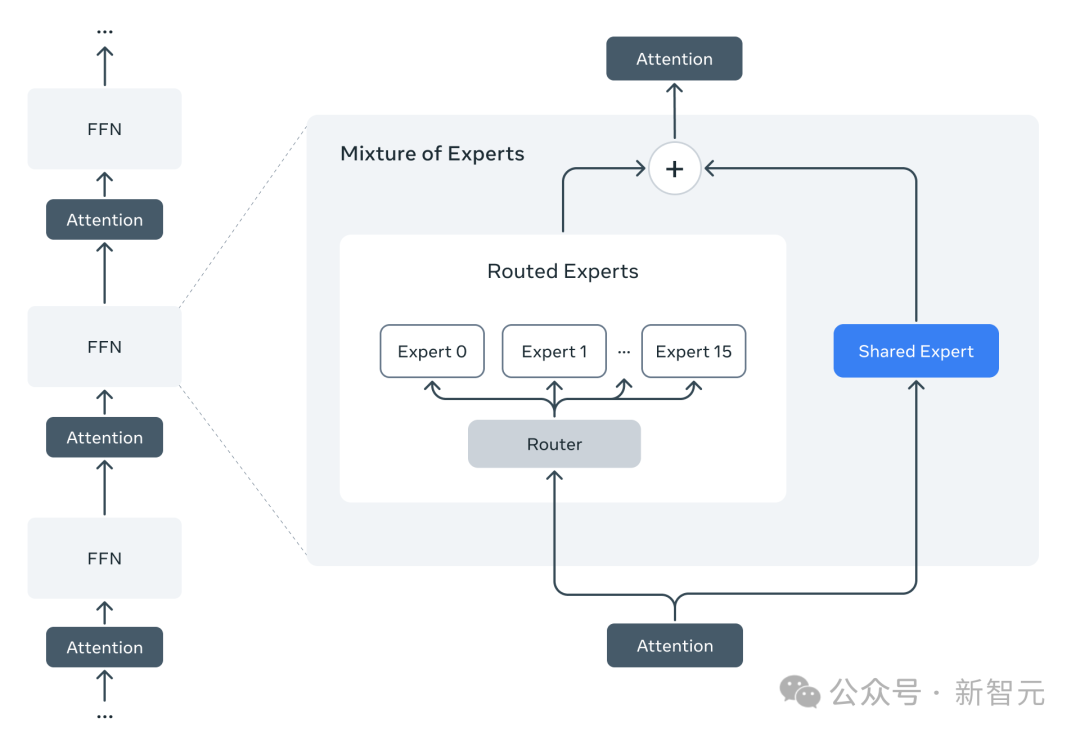
架构概览,右为混合专家(MoE)架构
举个例子,Llama 4 Maverick模型的4000亿个总参数中有170亿个活跃参数。
为了提高推理效率,Meta交替使用了稠密层和专家混合(MoE)层。
MoE层用到了128个路由专家和一个共享专家。每个token都会被送到共享专家,同时也会送到128个路由专家中的一个。
因此,虽然所有参数都存储在内存中,但在运行这些模型时,只有部分参数会被激活。
这样就能提升推理效率,降低模型服务的成本和延迟——
Llama 4 Maverick可以轻松部署在一台NVIDIA H100 DGX主机上运行,或者通过分布式推理来实现最高效率。
原生多模态设计
Llama 4是一个原生多模态模型,采用了早期融合技术,能把文本和视觉token无缝整合到一个统一的模型框架里。
早期融合是个大进步,因为它可以用海量的无标签文本、图片和视频数据一起来预训练模型。
Meta还升级了Llama 4的视觉编码器。这个编码器基于MetaCLIP,但在训练时跟一个冻结的Llama模型分开进行,这样能更好地调整编码器,让它更好地适配大语言模型(LLM)。
模型超参数优化
Meta还开发了一种叫做MetaP的新训练方法,能让他们更靠谱地设置关键的模型超参数,比如每层的学习率和初始化规模。
这些精心挑选的超参数在不同的批大小、模型宽度、深度和训练token量上都能很好地适配。
Llama 4通过在200种语言上预训练实现了对开源微调的支持,其中超过10亿个token的语言有100多种,整体多语言token量比Llama 3多出10倍。
高效的模型训练,解锁1000万输入上下文长度
此外,Meta注重高效的模型训练,采用了FP8精度,既不牺牲质量,又能保证模型的高FLOPs利用率——
在使用FP8精度和32K个GPU预训练Llama 4 Behemoth模型时,达到了每个GPU 390 TFLOPs的性能。
训练用的整体数据包含了超过30万亿个 token,比Llama 3的预训练数据量翻了一倍还多,涵盖了文本、图片和视频数据集。
Meta用一种叫做“中期训练”的方式来继续训练模型,通过新的训练方法,包括用专门的数据集扩展长上下文,来提升核心能力。
这不仅提高了模型的质量,还为Llama 4 Scout解锁了领先的1000万输入上下文长度。
后训练
最新的模型包含了不同的参数规模,满足各种使用场景和开发者的需求。
Llama 4 Maverick:参数规模较大,主要用于图像理解和创意写作
Llama 4 Scout:参数规模较小,适用多种任务,支持1000万token上下文,全球领先。
为了让不同模型适应不同的任务,针对多模态、超大参数规模等问题,Meta开发了一系列新的后训练方法。
主力模型Llama 4 Maverick
作为产品的核心模型,Llama 4 Maverick在图像精准理解和创意写作方面表现突出,特别适合通用助手、聊天类应用场景。
训练Llama 4 Maverick模型时,最大的挑战是保持多种输入模式、推理能力和对话能力之间的平衡。
后训练流程
为了训练Llama 4,Meta重新设计了后训练流程,采用了全新的方法:
轻量级监督微调(SFT)> 在线强化学习(RL)> 轻量级直接偏好优化(DPO)。
一个关键发现是,SFT和DPO可能会过度限制模型,在在线RL阶段限制了探索,导致推理、编程和数学领域的准确性不理想。
为了解决这个问题,Meta使用Llama模型作为评判者,移除了超过50%的被标记为“简单”的数据,并对剩余的更难数据进行轻量级SFT。
在随后的多模态在线RL阶段,精心选择了更难的提示,成功实现了性能的飞跃。
此外,他们还实施了持续在线RL策略,交替进行模型训练和数据筛选,只保留中等到高难度的提示。这种策略在计算成本和准确性之间取得了很好的平衡。
最后,进行了轻量级的DPO来处理与模型响应质量相关的特殊情况,有效地在模型的智能性和对话能力之间达成了良好的平衡。
新的流程架构加上持续在线RL和自适应数据过滤,最终打造出了一个行业领先的通用聊天模型,拥有顶尖的智能和图像理解能力。
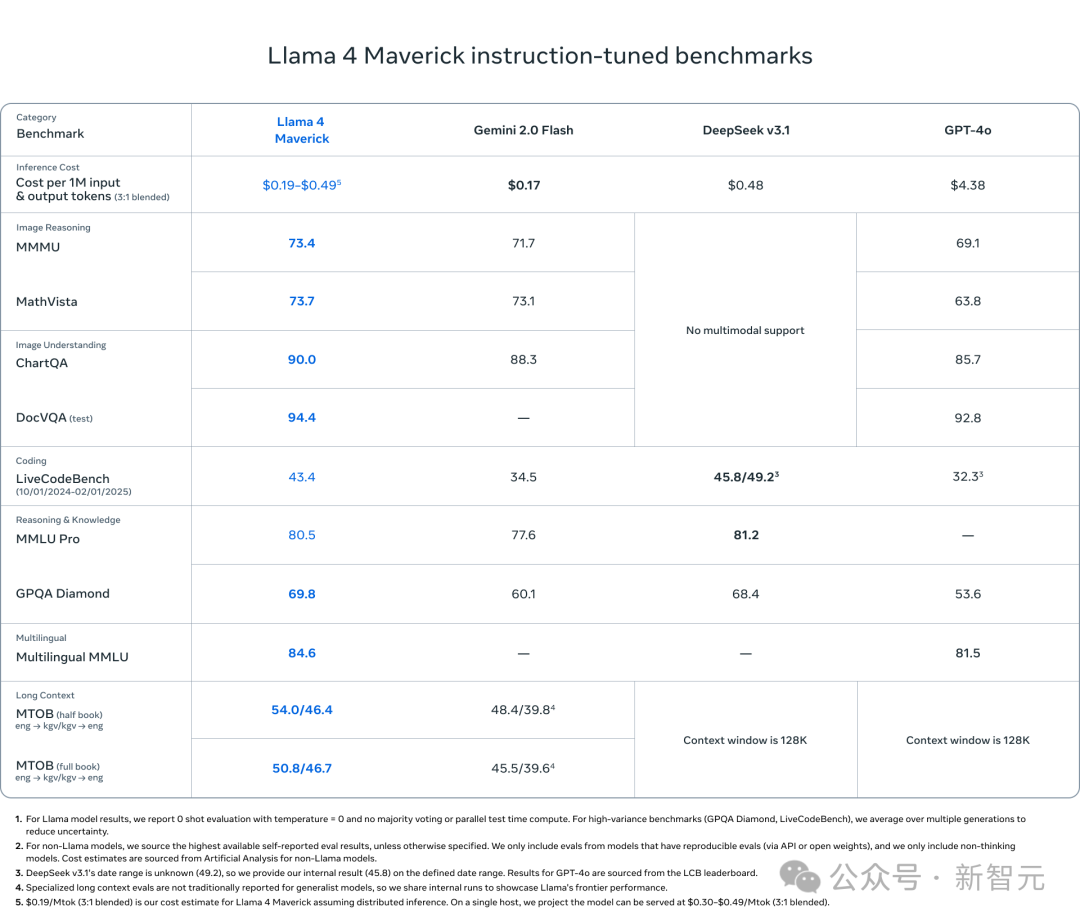
Llama 4 Maverick碾压GPT-4o和Gemini 2.0
作为一款通用的LLM,Llama 4 Maverick包含170亿个活跃参数,128个专家和4000亿个总参数,提供了比Llama 3.3 70B更高质量、更低价格的选择。
Llama 4 Maverick是同类中最佳的多模态模型,在编程、推理、多语言支持、长上下文和图像基准测试中超过了类似的模型,如GPT-4o和Gemini 2.0,甚至能与体量更大的DeepSeek v3.1在编码和推理上竞争。
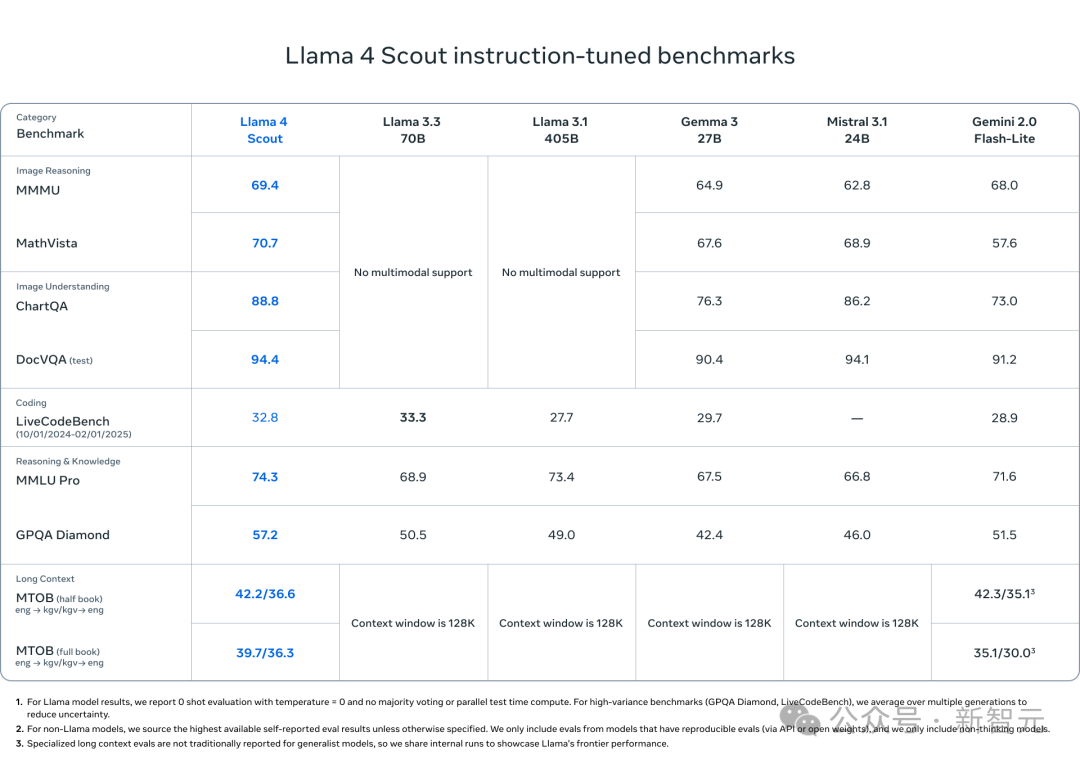
通用模型Llama 4 Scout:1000万token上下文
规模较小的Llama 4 Scout是一款通用模型,拥有170亿个活跃参数、16个专家和1090亿个总参数,在同类别中性能最好。
Llama 4 Scout 的支持上下文长度从 Llama 3 的12.8万激增到行业领先的1000万token。

这为多种应用打开了无限可能,包括多文档摘要、大规模用户活动解析以进行个性化任务,以及在庞大的代码库中进行推理。
Llama 4 Scout在预训练和后训练时都采用了256K的上下文长度,基础模型具备了先进的长度泛化能力。
它在一些任务中取得了亮眼成果,比如文本检索中的“大海捞针式检索”和在1000万token代码上的累积负对数似然(NLLs)。
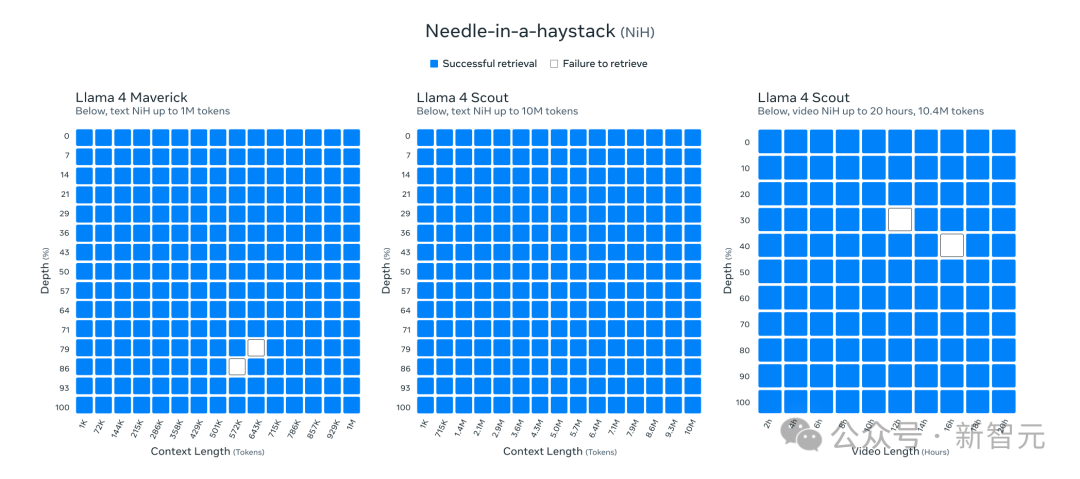
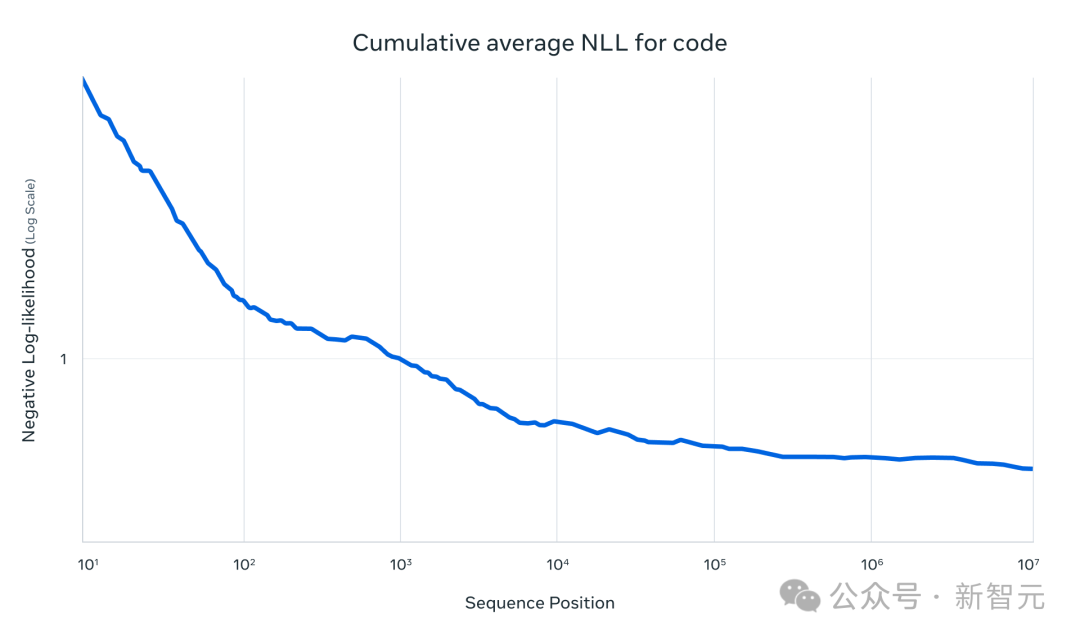
Llama 4架构的一个关键创新是使用了交替注意力层,而不依赖于位置嵌入。
此外,在推理时采用了温度缩放注意力,以增强长度泛化能力。Meta将其称为iRoPE架构,其中“i”代表“交替”(interleaved)注意力层,突出了支持“无限”上下文长度的长期目标,而“RoPE”则指的是在大多数层中使用的旋转位置嵌入(Rotary Position Embeddings)。
视觉理解能力
两款模型进行了大规模的图像和视频帧静态图像训练,以赋予它们广泛的视觉理解能力,包括对时间活动和相关图像的理解。
它们能够在多图像输入和文本提示的配合下,轻松进行视觉推理和理解任务。
模型预训练时最多用了48张图像,而在后训练测试中,最多8张图像也能取得不错的效果。
Llama 4 Scout在图像定位方面也是同类最佳,能够将用户的提示与相关的视觉概念对齐,并将模型的响应锚定到图像中的特定区域。
这使得更精确的视觉问答成为可能,帮助LLM更好地理解用户意图并定位感兴趣的对象。
编程、推理、长上下文和图像上,遥遥领先
Llama 4 Scout在编程、推理、长上下文和图像基准测试中超过了类似的模型,并且在所有以前的Llama模型中表现更强。
秉承对开源的承诺,Meta将Llama 4 Maverick和Llama 4 Scout提供给用户下载,用户可以在llama.com和Hugging Face上获取,之后这些模型还将在最广泛使用的云平台、数据平台、边缘硅片以及全球服务集成商上陆续上线。
2万亿巨兽,干掉GPT-4.5
Llama 4 Behemoth是一款“教师模型”,在同级别的模型里,它的智能水平相当高超。
Llama 4 Behemoth同样是一个多模态混合专家模型,拥有2880亿个活跃参数、16个专家以及近2万亿个总参数。
在数学、多语言处理和图像基准测试方面,它为非推理模型提供了最先进的性能,成为训练较小的Llama 4模型的理想选择。
教师模型+全新蒸馏
从Llama 4 Behemoth中蒸馏出来Llama 4 Maverick,在最终任务评估指标上大幅提升了质量。
Meta开发了一种新的蒸馏损失函数,在训练过程中动态地加权软目标和硬目标。
通过从Llama 4 Behemoth进行共同蒸馏,能够在预训练阶段分摊计算资源密集型前向计算的成本,这些前向计算用于计算大多数用于学生模型训练的数据的蒸馏目标。
对于学生训练中包含的额外新数据,会在Behemoth模型上运行前向计算,以生成蒸馏目标。
后训练
对一个拥有两万亿参数的模型进行后训练也是一个巨大的挑战,这必须彻底改进和重新设计训练方案,尤其是在数据规模方面。
为了最大化性能,不得不精简95%的SFT数据,相比之下,较小的模型只精简了50%的数据,目的是确保在质量和效率上的集中关注。
Meta还发现,采用轻量级的SFT后接大规模RL能够显著提高模型的推理和编码能力。Meta的RL方案专注于通过对策略模型进行pass@k分析来采样难度较大的提示,并设计逐渐增加提示难度的训练课程。
在训练过程中动态地过滤掉没有优势的提示,并通过从多个能力中混合提示构建训练批次,对提升数学、推理和编码的性能起到了关键作用。
最后,从多种系统指令中采样对于确保模型保持良好的指令跟随能力,在推理和编码任务中表现出色也至关重要。
扩展RL训练
对于两万亿参数的模型,扩展RL训练也要求重新设计底层的RL基础设施,应对前所未有的规模。
Meta优化了MoE并行化的设计,提高了速度,从而加快了迭代速度。
Llama团队开发了一个完全异步的在线RL训练框架,提升了灵活性。
与现有的分布式训练框架相比,后者为了将所有模型都加载到内存中而牺牲了计算内存,新基础设施能够灵活地将不同的模型分配到不同的GPU上,根据计算速度在多个模型之间平衡资源。
这一创新使得训练效率比之前的版本提升了约10倍。
Llama 4一夜成为开源王者,甚至就连DeepSeek V3最新版也被拉下神坛,接下来就是坐等R2的诞生。